An Event Detection dataset
Content
|
This section presents, via the left menu, a description of the test sequences for each category along with frame samples, low resolution video previews and the event annotations. Annotations have been done using the VIPER toolkit. The video files have been coded using the MPEG-1 codec in order to be compatible with the VIPER toolkit Currently, the dataset contains 17 sequences taken using a stationary camera at resolution of 320x240 at 12 fps. The dataset is focused on two types of human-related events: interactions and activities. In particular, two activities (Hand Up and Walking) and three human-object interactions (Leave, Get and Use object) have been annotated. We have grouped all the test sequences into three categories according to a subjective estimation of the analysis complexity considering:
Sample frames of such categories are shown in the following images A
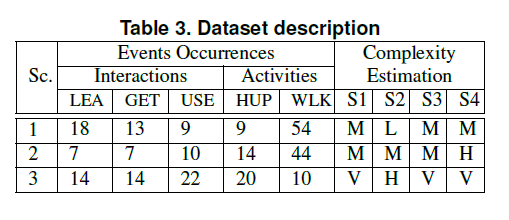
summary of the annotated events in the dataset
and the associated complexity of each category is available in the
following table The
complexity estimation codes are Low (L), Medium (M), High (H) and
Very High (V). The events are Leave-object (LEA), Get-object (GET),
Use-object (USE), Hand Up (HUP) and Walking (WLK).
|