An Abandoned and Stolen Object Discrimination dataset
Content
|
This section presents, via the left menu, a description of the test sequences for each category along with frame samples, low resolution previews and the event annotations.
The dataset consists on two sets of annotations of the foreground binary masks of the abandoned and stolen objects. The first one has been obtained by manually annotating the objects of interest in the video sequence (annotated data). The second one represents real data has been obtained by running [1] over the test sequences and represents unaccurate masks (real data).
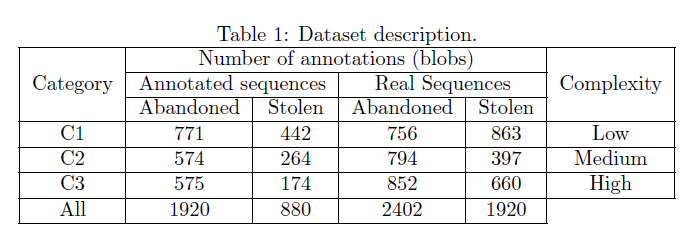
We have grouped all the test sequences into three categories according to a subjective estimation of the background complexity that consists on the presence of edges, multiple textures, lighting changes, reflections, shadows and objects belonging to the background. Currently, three categories have been defined considering Low (C1), medium (C2) and High (C3) background complexity.
Sample
frames of such categories are shown in the following images A
summary of the annotated events in the dataset
and the associated complexity of each category is available in the
following table [1] J.C. SanMiguel
and J.M. Martínez, "Robust unattended and stolen object
detection by fusing simple algorithms", Proc. of IEEE Int. Conf. on
Advanced Video and Signal based Surveillance, AVSS2011, SantaFe (NM,
USA), pp. 18-25.
|